0 Likes
A Simple Way to Prevent Neural Networks from Overfitting
Last updated on April 6, 2021, 8:07 p.m. by vinit
This paper analyzes the effect of dropout on different properties of a neural network and describes how dropout interacts with the network's hyperparameters.
Although dropout alone gives significant improvements, using dropout along with max norm regularization, large decaying learning rates and high momentum provides a significant boost over just using dropout.
The best performing convolutional nets that do not use dropout achieve an error rate of 3.95%. Adding dropout only to the fully connected layers reduces the error to 3.02%. Adding dropout to the convolutional layers as well further reduces the error to 2.55%. Even more gains can be obtained by using maxout units.
Method ConvNet max pooling stochastic pooling max pooling max pooling dropout fully connected layers max pooling dropout in all layers maxout CIFAR-10 CIFAR-100 15.60 15.13 14.98 14.32 12.61 11.68 43.48 42.51 41.26 37.20 38.57 Table 4: Error rates on CIFAR-10 and CIFAR-100.
A 4-layer net pretrained with a stack of RBMs gets a phone error rate of 22.7%. With dropout, this reduces to 19.7%. Similarly, for an 8-layer net the error reduces from 20.5% to 19.7%. Method Phone Error Rate% NN Dropout NN 23.4 21.8 DBN-pre trained NN DBN-pre trained NN DBN-pre trained NN mcRBM-DBN-pre trained NN DBN-pre trained NN dropout DBN-pre trained NN dropout 22.7 22.4 20.7 20.5 19.7 19.7
Results on a Text Data Set To test the usefulness of dropout in the text domain, we used dropout networks to train a document classifier.
We 1942 Dropout Method Test Classification error % L2 L2 L1 applied towards the end of training L2 KL-sparsity Max-norm Dropout L2 Dropout Max-norm 1.62 1.60 1.55 1.35 1.25 1.05. Comparison of different regularization methods on MNIST. also see how the advantages obtained from dropout vary with the probability of retaining units, size of the network and the size of the training set.
In our experiments, we use CD-1 for training dropout RBMs. Effect on Features Dropout in feed-forward networks improved the quality of features by reducing co-adaptations.
Important points:
- Deep neural nets with a large number of parameters are very powerful machine learning systems.
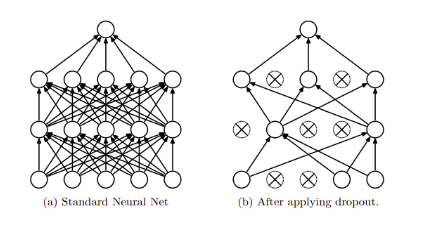
- However, overfitting is a serious problem in such networks. Large networks are also slow to use, making it difficult to deal with overfitting by combining the predictions of many different large neural nets at test time. Dropout is a technique for addressing this problem.
- The term “dropout” refers to dropping out units (hidden and visible) in a neural network. By dropping a unit out, we mean temporarily removing it from the network, along with all its incoming and outgoing connections
- The idea of dropout is not limited to feed-forward neural nets. It can be more generally applied to graphical models such as Boltzmann Machines.
- Dropout neural networks can be trained using stochastic gradient descent in a manner similar to standard neural nets.
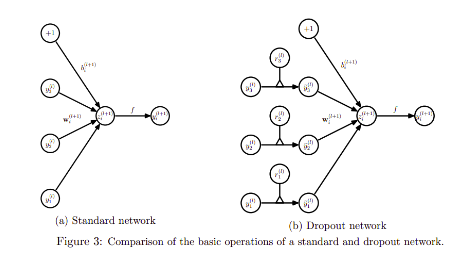
- The only difference is that for each training case in a mini-batch, we sample a thinned network by dropping out units. Forward and backpropagation for that training case are done only on this thinned network.
- The pretraining procedure stays the same. The weights obtained from pre training should be scaled up by a factor of 1/p.
- We trained dropout neural networks for classification problems on data sets in different domains. We found that dropout improved generalization performance on all data sets compared to neural networks that did not use dropout.
- Dropout can be seen as a way of doing an equally-weighted averaging of exponentially many models with shared weights.
- The experiments described in the previous section provide strong evidence that dropout is a useful technique for improving neural networks.
0 Likes


Suggested Posts


